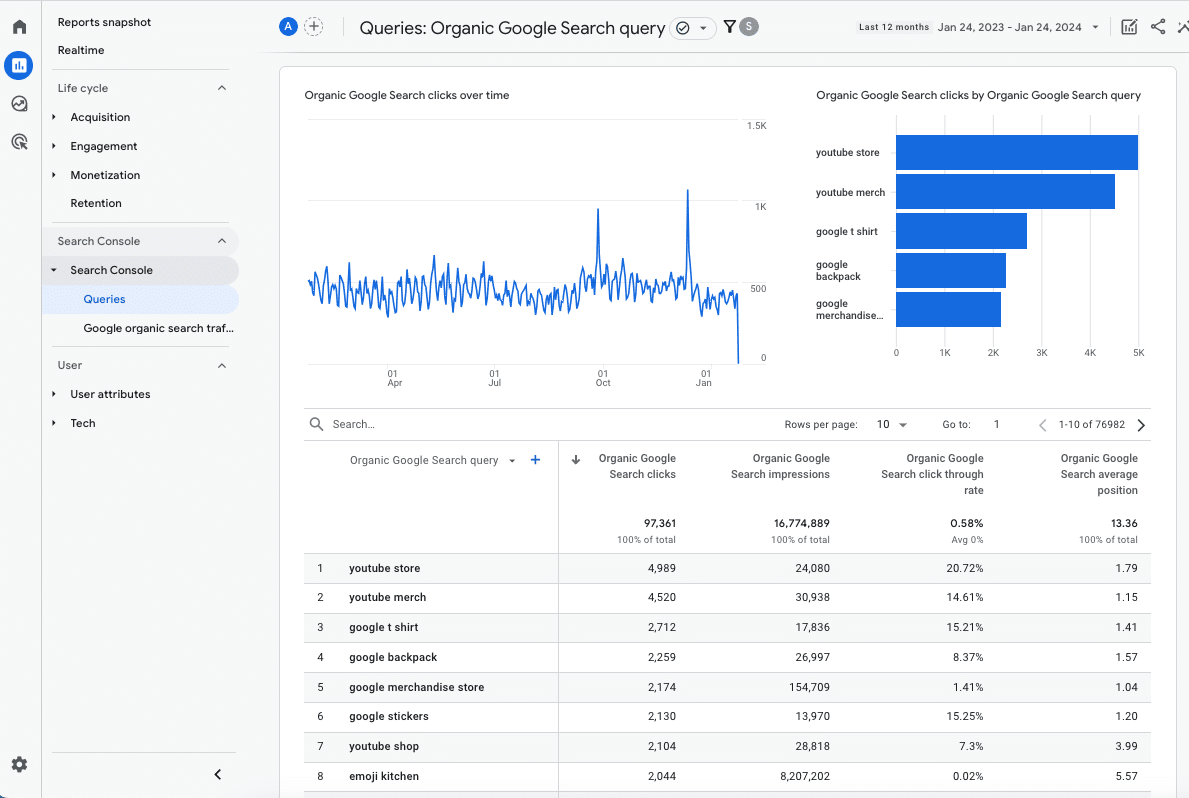
TikTok videos have been spotted in two prominent locations in Google’s Search results – featured snippets and Search Generative Experience (SGE).
While I’m not entirely sure if this is “new,” I’ve never seen this before and this is definitely new to many people in the search community.
Why we care. Many people have been having a semantic debate over whether TikTok technically is a “search engine.” What actually matters is that people use TikTok to search. Your brand/business could potentially be losing out on ways to reach your audience – on TikTok, Google, or both. Especially now, where it seems Google is giving TikTok videos some prominent SERP real estate.
TikTok videos in featured snippets. Louise Parker, head of PR at Propellernet, shared a screenshot on LinkedIn for a search for [stroking baby’s eyebrows], where the snippet is taken directly from a TikTok video’s caption:

TikTok videos in SGE. Separately today, Carrie Rose, CEO and founder of Rise at Seven, shared a screenshot on LinkedIn of TikTok content being displayed in an SGE result:
![Google Search results for [do cows eat donuts or doughtnuts] that include a TikTok video in Search Generative Experience results.](https://searchengineland.com/wp-content/seloads/2024/01/cows-donuts-google-sge-tiktok.jpg)
TikTok videos in SERPs. TikTok videos aren’t new to Google SERPs. In 2020, Google started showing TikTok videos in a Short videos carousel and a TikTok video carousel on mobile.
Microsoft Bing Search has also promoted TikTok video results.
Gen Z uses TikTok to Search. While people continue to debate whether TikTok is a search engine, what you need to know is consumers (especially Gen Z) could care less about. Dig deeper in Survey: 51% of Gen Z women prefer TikTok, not Google, for search.
Adobe also released results of a survey of 808 consumers earlier this month that found:
- 2 in 5 Americans use TikTok as a search engine.
- Nearly 1 in 10 Gen Zers are more likely to rely on TikTok than Google as a search engine.
a message brought to you by Wayne Vass SEO
This article first appeared on: The post %%POSTLINK%% appeared first on %%BLOGLINK%%.











 RSS Feed
RSS Feed
